
An Introduction to Infrastructure as Code with Terraform

Imagine this, it's a Tuesday, you've just finished developing a feature, it passed all the checks, and you're ready to deploy.
You merge the changes, and soon after you notice that the deployment to two servers succeeds, but the third fails.
This isn't a new scenario. You begin debugging and find the error you were looking for:
Missing dependenies
Despite the frustration, you manually fix the issue and redeploy successfully.
If this situation sounds familiar, you're not alone. It's common in development, but it doesn’t have to be.
This article introduces how using infrastructure as code tools can prevent these inconsistencies and streamline your deployment process.
A brief history of provisioning IT infrastructure
Before we get to all the fancy stuff, let's look at why such tools were created.
Before infrastructure as code (IAC) tools, you had three ways to provision and manage IT infrastructure:
Using the UIs provided to you by cloud providers

You would have access to the UI of a cloud provider (AWS, Azure, or GCP) directly and set things up with the UI.
This process can be very tedious and you have to memorize the steps you've taken for multiple different environments.
Using the CLIs provided to you by cloud providers
This is essentially the same as using the UI but instead of clicking on buttons, you run commands.
All popular cloud providers have their own CLI tool. You can use it to provision the infrastructure components that you want.
This approach can be automated, you can create a script to run a series of commands but can quickly get very complicated due to the nature that the CLI tool does not manage state. So you have to do that yourself.
You're also locked into the specific CLI tool of the cloud provider.
Doing things manually with the help of automation tools

In some cases, you don't want to use any cloud providers and instead provison and manage your own physical or virtual servers.
There's a lot of manual work here but almost everything can be automated using scripts and tools such as Ansible, Puppet, Chef, etc...
But these can go out of hand too, your operations team will have to manage all that and there is a clear knowledge barrier so you'll have to keep this safe from unnecessary change.
As you can see the three approaches contain a lot of manual work and there are lots of different things that can go wrong due to us being humans.
IT companies realized this and proposed the question.
Why don't we just use code?
Yes, but not the code you're thinking of.
We want declarative code, code that states what it wants and the program will magically provision our infrastructure for us. It will also ideally manage state and be easy and intuitive to use.
This type of code is called Infrastructure as Code (IAC).
Let's take a closer look at the benefits of defining things with code.
Benefits of defining things with code.
Mindset Shift
Companies used to treat infrastructure as secondary to product. But now with the addition of IAC, infrastructure can be treated the same way as product code. This means that whatever improvements you can get with software products, you can do the same with IAC.
So things like PR checks, version control, and automation are all possible once we treat our IAC as a software engineering endeavor.
Version Control
In the past, you didn't exactly know what was on production. You can log in to the AWS UI and see the individual components or use the CLI but that would take a lot of effort.
You could have multiple different environments with slightly different configurations. You could have products with different infrastructure needs. To get an overview of what you have would be no easy feat.
But with IAC, you could utilize version control systems such as Git to host your configurations on GitHub, Gitlab, etc...
This way you have a single source of truth with the added benefit of collaboration. Your colleagues can now join in configuring infrastructure by pulling the repository, working on it, pushing it to a new branch, and creating a PR.
Just like normal software development.
Automation
There are a lot of good automation workflows that can be done because your code is version-controlled.
You can add linters and validation checks to your PRs. You could even spin up a temporary environment to test your changes.
You could incorporate testing using tools like TerraTest that can run in your PR pipeline.
Apart from testing, you could take things one step further and automate your deployments. So once a PR is merged, you could run a pipeline that will plan and apply your changes. You could also store your state files in some artifact repository for debugging or versioning purposes.
Knowledge Sharing
When things are being done manually, it usually is the operations team that has all the knowledge of how things are being done.
In extreme case, scenarios it's a few people in the operations team that know how things are being managed.
This proves to be very risky for companies as if these people leave then there will be a huge knowledge gap in the company.
This all gets fixed with IAC because of version control. The configurations are public and you can always refer to the code to understand what's happening.
PS. You would need to know how the IAC works and information about the specific resources to understand what is going on but that is pretty straightforward.
Breaking Silos
IAC forces operations people to think more like software engineers and software engineers to learn more about operations.
This breaks the silos between the departments and encourages cross-collaboration. The benefits of this include:
- Faster and safer delivery of products – This is due to both departments understanding what the other person is doing. This results in operations optimizing their work for developers and software engineers optimizing their work for operations.
- Knowledge sharing – Both departments work with each other and they learn more about each other fields. This makes the engineering culture within the company much more open to learning and makes the company a better place to work.
Risk Reduction
Manual work is very error-prone. That's why factories were created in the real world. The same thing can be said about software tasks done manually.
Our factories are called automation. Using IAC tools we automate managing and provisioning of infrastructure.
Our only job is to create the blueprint or the "plan". Once that is done, you can run your automation indefinitely and it will always be the same.
That's why IAC is vital if you wanna deploy to multiple regions or environments. You could have one blueprint for different regions of the world.
When to not define things with code.
IACs are not perfect, there are cases in which they simply don't work and cases where they are too expensive to do. Below I've summarised the most common reasons to avoid IACs.
- Resources that are too simple – Sometimes you have a simple infrastructure with a few services and you don't foresee yourself scaling in the future. In that case, it's better to just do things manually and once you need to scale, you can move to an IAC approach.
- Resources that are not intuitive enough with code – Sometimes resources are very hard to describe in code. It would just be a lot easier to use some sort of UI for that specific resource.
- Resources with bad tooling – Sometimes it's just not possible to go with the IAC approach due to the lack of tooling of a resource.
- When you have a small team – IACs shine when you have a complex infrastructure with many teams and services. But if it's just a simple application, then I'll suggest going to the platform as a service approach.
Terraform
![What is Terraform Cloud? Complete Terraform Tutorial [New]](https://www.whizlabs.com/blog/wp-content/uploads/2021/04/Terraform-1.png)
Now that we are done with the theory of IACs, let's take a look at the pioneer of IAC tools, Terraform.
Terraform is a tool that allows you to provision, manage, and version resources in a declarative fashion.
So why do I say resources instead of infrastructure components?
Because Terraform works with pretty much anything that has an accessible API. I'll get into the details of how Terraform works later but you could wrap your API into a Terraform provider that you can use to provision and manage your resources.
Here are some examples of Terraform providers:
- Infrastructure as a service – AWS, GCP, Azure, and Alibaba.
- Platform as a service – Heroku, Confluent, Ably, and Fastly.
- Software as a service – Github, Pagerduty, Datadog, and Grafana.
So in a nutshell a resource can be anything that is defined in a provider. It can be a GitHub repository, an EC2 instance, or a Kafka cluster.
Terraform Workflow.
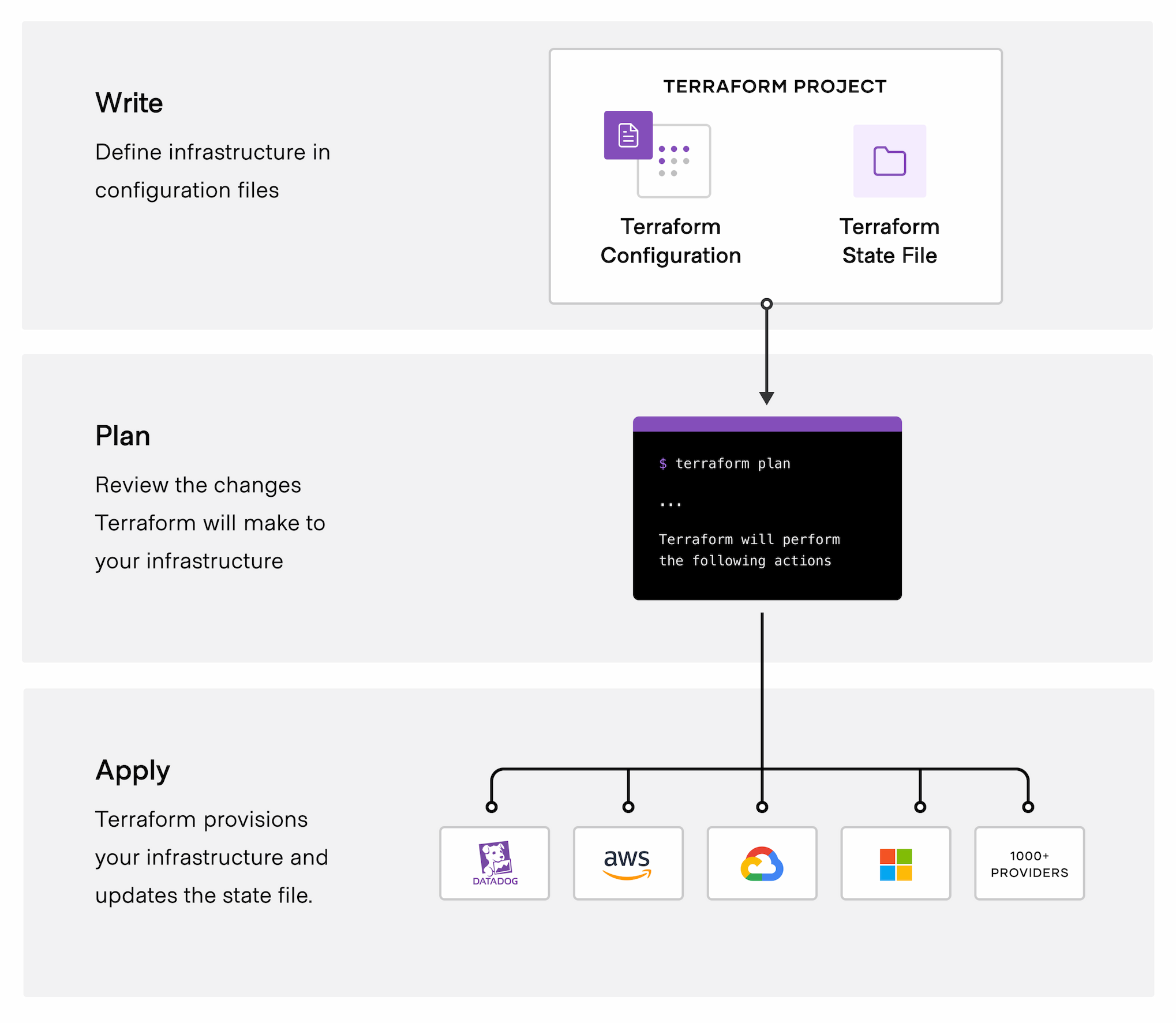
Before covering the internals of Terraform. I want to quickly go over the Terraform workflow from a user's perspective.
Terraform is a program that you install on your local machine that contains the Terraform CLI, which you will use to run Terraform.
Terraform allows you to define your resources using its declarative language called HashiCorp Configuration Language (HCL). You would write this code in a .tf file.

Init
After you have written your configuration, the first command you will run is terraform init. It will initialize a working directory containing terraform configuration files.
It will also install the necessary providers that you have specified in your code. If you run it again, then it will update the providers.
Plan
Terraform will look at what we have in the current state and compare it to our desired state (what we have in our configurations). It will then generate a plan on how it plans to make the current state into the desired state.
As Terraform treats resources immutably, it can only create or delete resources. It updates resources by creating a new resource and replacing the old one. The reason it does is that I'll cover that in the section below.
Let's take an example, let's say I want to create a Kubernetes namespace for the first time. I'm gonna first define my namespace in a terraform configuration file and run the plan command. It will then generate something like this:
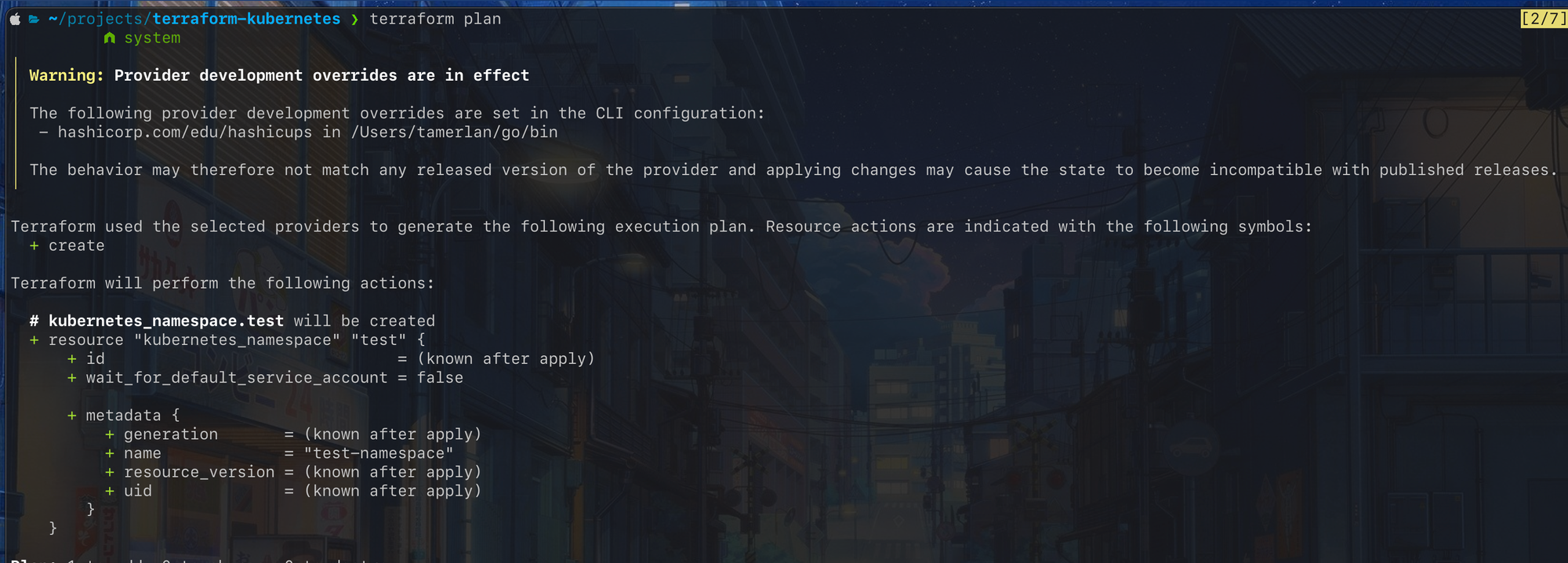
As you can see, this will create a new Kubernetes resource called test.
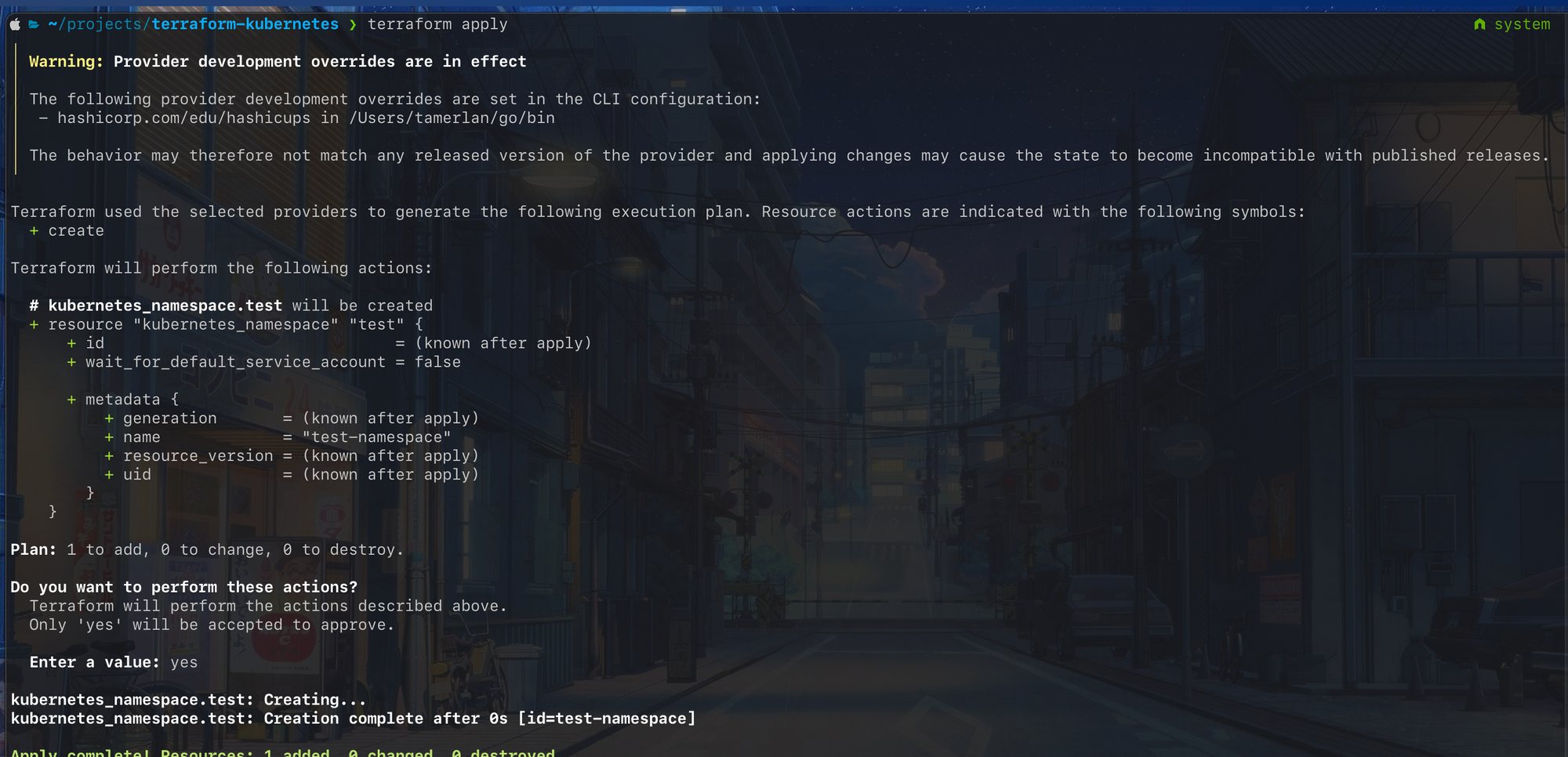
Apply
The apply command simply executes the plan that was generated before. You don't have to run the plan command first but it is highly advisable to do to avoid any human errors.
The output of the apply command will look something like this:
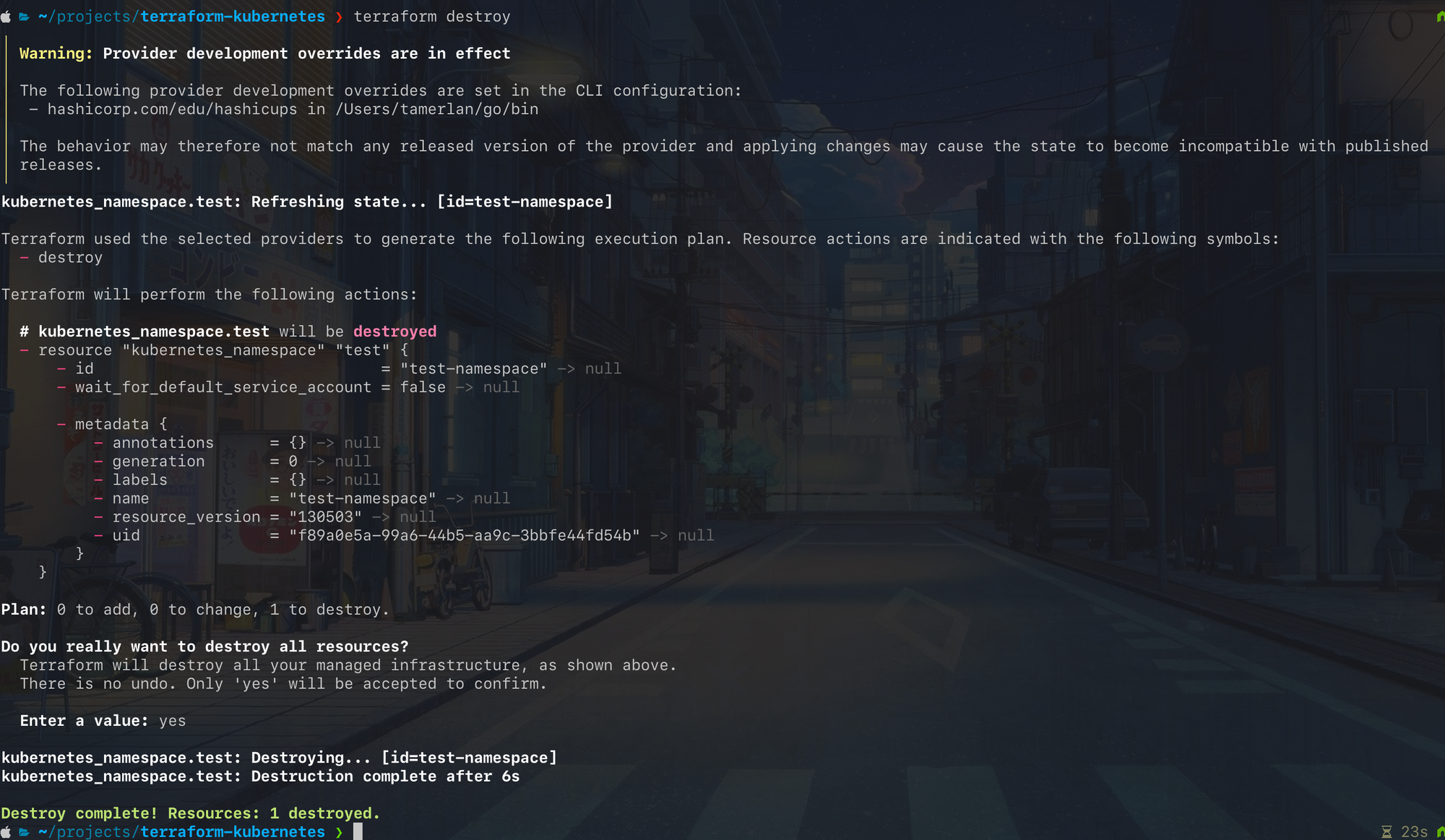
Destroy
Everything must come to an end and Terraform makes that process as simple as possible. You can delete resources using the terraform destroy command.
Underneath the hood, the destroy command is a plan command with an empty desired state combined with an apply command.
Let's delete the namespace that we just created.
Other useful Terraform commands
- Refresh – Fetches the current state and updates the local state file. (I'll talk more about the state file below).
- Validate – Verifies whether a configuration is syntactically valid and internally consistent.
To learn more about Terraform's workflow, feel free to watch this video:
A brief look at Terraform's architecture.

The extensibility of Terraform comes from its architectural decisions. They've decided early on that they don't manage providers directly but provide a platform on which providers can be easily created.
The way it does that by separating two core components:
- Terraform Core – The terraform binary that communicates with plugins to manage resources.
- Plugins – Plugins are executable binaries written in Go that communicate with Terraform over an RPC interface. Terraform currently supports only one type of plugin called providers. Providers are essentially an implementation of a specific service or tool, such as AWS.
Another key aspect of Terraform is how it treats its resources. All resources are immutable, meaning that they cannot change.
So if you want to update a resource, then Terraform will simply spin up a new instance of the resource with the updated config and replace the old one with it.
The reason why it does that is for simplicity's sake. If you have v1 and v2 versions of your infrastructure, it will guarantee that what is deployed is either v1 or v2.
On the other hand, if you treat resources mutably then it would be Terraform's job to update the infrastructure from v1 to v2. Some steps can succeed while others fail, so you might end up with a v1.5. Debugging this is a huge pain for both users and Terraform so that's why it chose the immutable approach.
To learn more, feel free to watch this video.
The last thing I wanted to touch upon is the notion of a state file. Terraform must know the current state of your resources and to do that it must ask the provider.
The provider will return the current state of the resources by calling the backend API. Sometimes this is slow, or there are rate limits. So Terraform makes sure to cache whatever state it has onto a state file. It's essentially a JSON file with the information about the resources.
Let's manage our k8s cluster with Terraform.
Now that we know what is IAC and Terraform, let's play around with it. For this demo, you'd need to have access to a Kubernetes cluster from your terminal and have Terraform installed.
To install Terraform, refer to the documentation here.
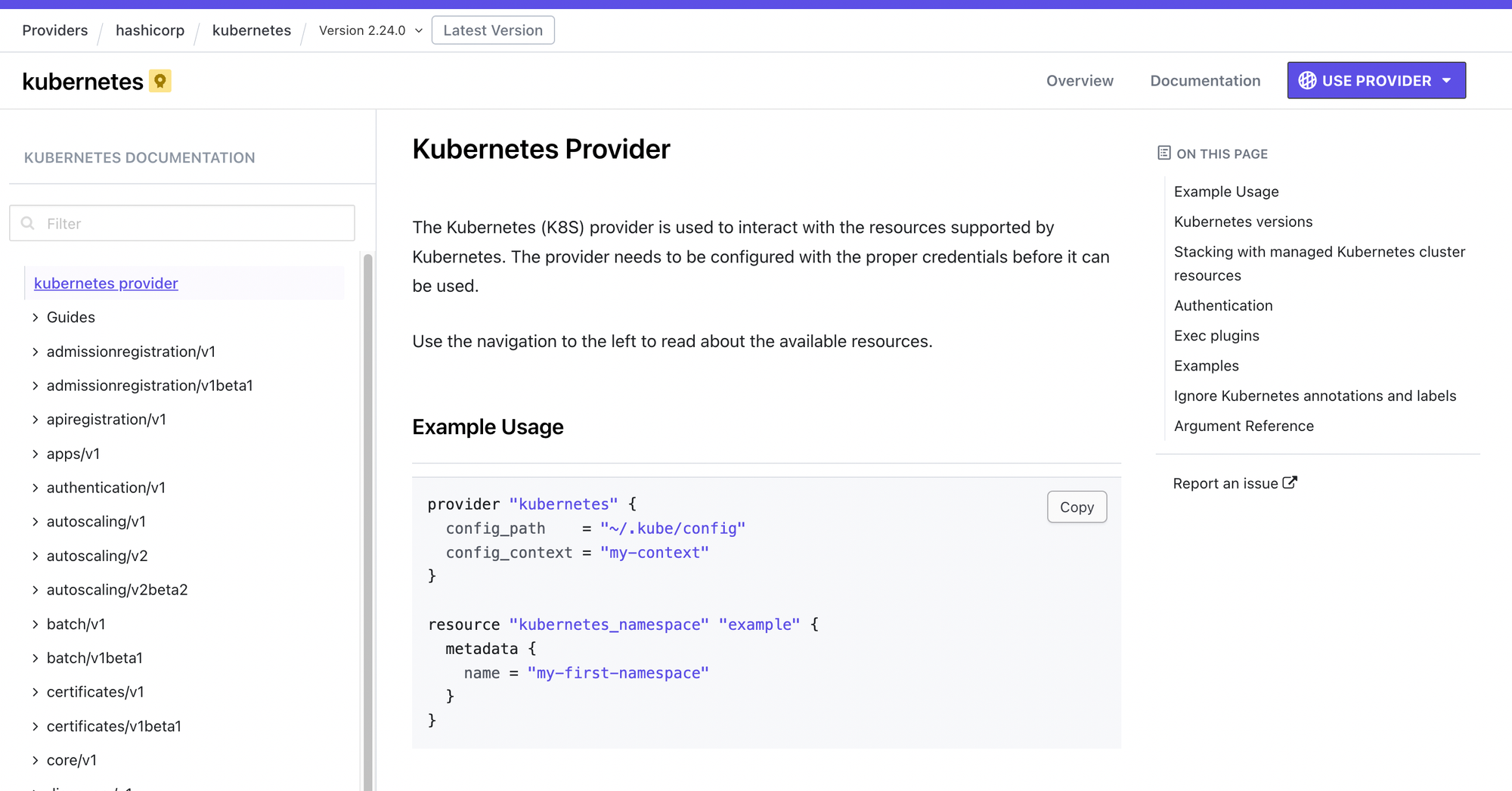
The provider we will use is the official Kubernetes provider by Hashicorp.
Writing our code
Let's begin by creating a directory for our project.
mkdir terraform-demo
cd terraform-demo/Next, let's create our configuration file.
touch main.tf PS. I'd highly suggest installing the Terraform plugin for VSCode or the Terraform LSP if you use Vim. I suppose other popular IDEs like Jetbrains will also have a Terraform plugin. This will help with autocompletion, syntax highlighting, and diagnostics.
Looking at the Kubernetes provider documentation, this is how it will look to initialize the provider and point it to my local Kubernetes cluster.
terraform {
required_providers {
kubernetes = {
source = "hashicorp/kubernetes"
version = ">= 2.0.0"
}
}
}
provider "kubernetes" {
config_path = "~/.kube/config"
config_context = "kind-crossplane"
}
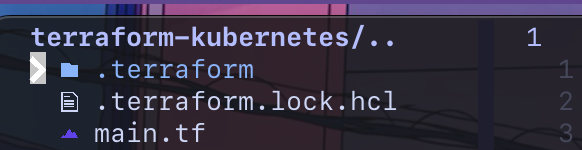
Now do a terraform init and it will initialize a terraform project and install the Kubernetes provider.
You should now see a folder named terraform with your installed provider and a terraform.lock.hcl.
Now we are ready to create resources. I'll create a Kubernetes deployment and service with a dummy Nginx image. From here on out, it's about domain-specific knowledge. So for whatever provider you using, make sure to check out its documentation and see what resources you can create.
My main.tf file looks like this now:
terraform {
required_providers {
kubernetes = {
source = "hashicorp/kubernetes"
version = ">= 2.0.0"
}
}
}
provider "kubernetes" {
config_path = "~/.kube/config"
config_context = "kind-crossplane"
}
resource "kubernetes_namespace" "test" {
metadata {
name = "test-namespace"
}
}
resource "kubernetes_deployment" "test" {
metadata {
name = "nginx"
namespace = kubernetes_namespace.test.metadata[0].name
}
spec {
replicas = 2
selector {
match_labels = {
app = "MyTestApp"
}
}
template {
metadata {
labels = {
app = "MyTestApp"
}
}
spec {
container {
image = "nginx"
name = "nginx-container"
port {
container_port = 80
}
}
}
}
}
}
resource "kubernetes_service" "test" {
metadata {
name = "nginx"
namespace = kubernetes_namespace.test.metadata[0].name
}
spec {
selector = {
app = kubernetes_deployment.test.spec[0].template[0].metadata[0].labels.app
}
type = "NodePort"
port {
node_port = 30201
port = 80
target_port = 80
}
}
}
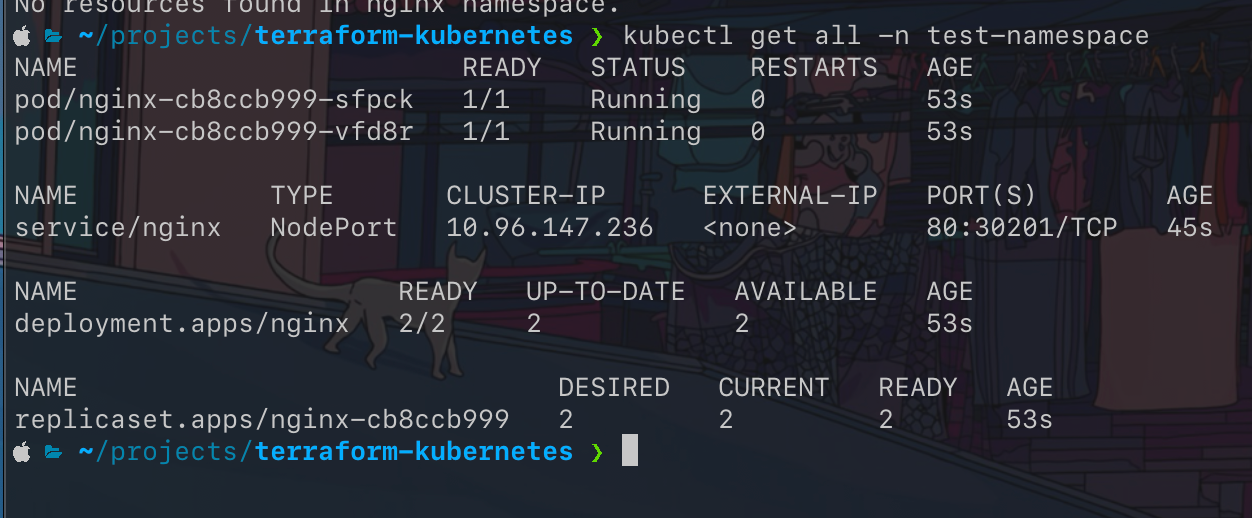
If we run terraform plan and terraform apply it will create for me the resources I wanted.
Conclusion
We've covered a lot but this should just be the beginning of your Terraform journey. So make sure to play around with Terraform. Once you feel comfortable with using it, I'd suggest learning the following:
- Learn how to abstract multiple resources into one using Terraform Modules.
- Develop your own providers and learn to get a deeper understanding of Terraform. You can find the documentation for provider development here.
- Explore Terraform alternatives:
I hope you enjoyed this article, if you have any questions then feel free to message me on Twitter @tamerlan_dev
Thank you for reading.
No spam, no sharing to third party. Only you and me.
Member discussion