Multithreading Principles and Patterns

As I was studying Operating Systems, I learned about multithreaded applications and how they work. I was pleasantly surprised to see that they got their own design patterns.
As the guy with around 9 articles on different design patterns, I just had to write something about it.
Well here goes nothing...
Today I will summarize all the popular multithreaded principles and design patterns.
What are multithreading patterns?
Multithreaded programming is very sensitive.
Many things can go wrong and they are pretty hard to debug.
Issues such as deadlocks and stalling your data are pretty common if you're not careful.
That's why, a bunch of smart programmers, over the years have created patterns to design multithreaded code better.
They are pretty much the same thing as design patterns but for multithreaded applications.
Useful Principles for Multithreaded Programming
Immutable Objects
Immutable objects cannot be changed. Their state stays the same. The only way to "change" them is to first create a copy of the object and then pass it in the new state.
Immutable objects are useful because:
- They are thread-safe, meaning that they manipulate shared data in a multithreaded environment properly.
- They are simple to understand.
- They offer a high level of security.
- Functions have no side effects.
This pattern is so popular that a whole other branch of programming called functional programming uses immutable objects by default.
But there are drawbacks, it can be:
- Pretty costly to create separate objects for each change.
- Impractical to make some objects immutable due to how much they change.
- A pain to implement.
In short, immutability is good for objects that behave like values or only have a few properties. Before making anything immutable, you must consider the effort needed and the usability of the class itself after making it immutable.
You can read more about immutable objects here:
 Contributors to Wikimedia projects
Contributors to Wikimedia projectsCommand Query Separation Principle
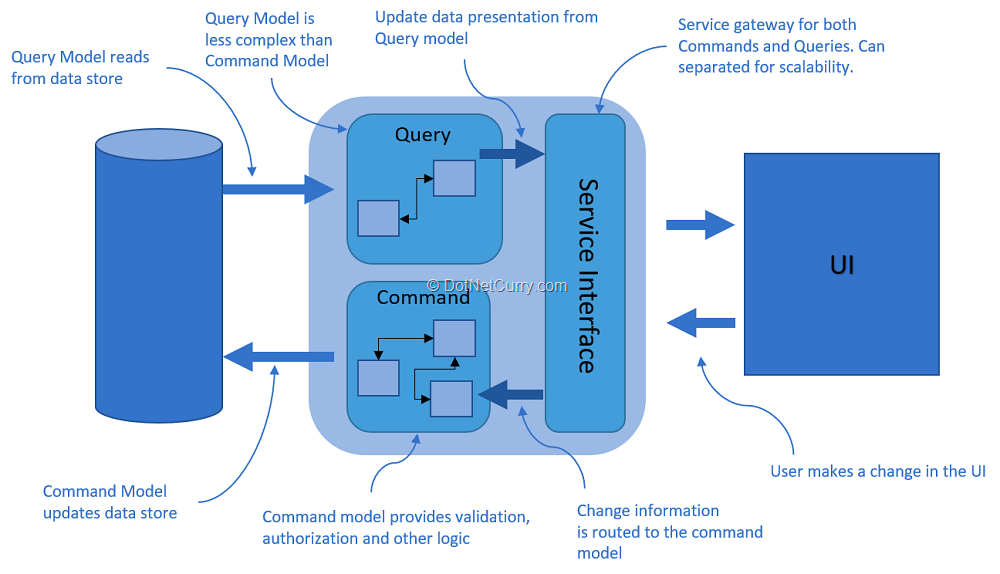
The command query separation (CQS) principle states that all methods of an object should either be:
- A query where you return data but not modify state.
- A command where you modify state but don't return data.
The advantages of this approach are:
- Separation of Concerns – Your code will be more structured, hence motivating you to follow more SOLID code and write more unit tests.
- Performance Optimizations – Because our reads and writes are separated, we can optimize performance much more easily. This is more valuable on the read side because most applications are more read centric.
- CQRS – CQRS is an extension of CQS but on a more architectural level. Because our code is more structured, we can utilize different "practices" for reads and writes. For example, instead of using a SQL database for our reads, we can use a NoSQL one.
- Implementation – This principle is easy to implement.
As always nothing is perfect. I don't suggest using this pattern religiously sometimes it's more beneficial to return data in a command. For example, the array pop method in most programming languages breaks this pattern but nonetheless, it's a pretty useful one.
To read more on CQS, I suggest reading this article by Martin Fowler.
Other Tips on Multithreaded Programming
- Take huge benefit of the language and library features you are using such as concurrent lists and threading structures because they are well designed and have good performance.
- If you're new to multithreading, start out small and keep things simple - take the time to really understand exactly how your threads are interacting with each other - what threads will be doing the same things at the same time, and what threads will be waiting on each other.
Multithreading Design Patterns
This part of the article is meant to be more of a reference, so feel free to skip around.
PS. All code examples will be in pseudocode because most of these patterns are universal.
Active Object (Actor Pattern)

The active object is a design pattern that introduces concurrency by decoupling method execution from method invocation.
But you might say, "aren't method execution and invocation the same thing?"
Technically yes, but no.
Let me explain.
Invocation time is the time required to invoke or call the method. Execution time is the time required to execute the body of the method.
So what this pattern does is that it separates calling the method from its executing body.
Okay smartass, how do we actually do that?
Well, this pattern has four key elements:
- Proxy (or Client Interface) – An interface provided to clients which define the public methods of our active object.
- Dispatch Queue – A list of pending requests from clients.
- Scheduler – Decides which request to execute next.
- Result Handle (or Callback) – This allows the result to be obtained by proxy after a request is executed.
The pseudocode will look something like this:
class ActiveObject {
count = 0
dispatch_queue = new DispatchQueue()
constructor(){
// Initialize and run thread
thread = Thread(this.run_tasks)
thread.start()
}
function run_tasks() {
while(true){
if(this.dispatch_queue not empty){
this.dispatch_queue.take().run()
}
}
}
function increment_count(){
this.dispatch_queue.add(function run(){
this.count++
})
}
function decrement_count(){
this.dispatch_queue.add(function run(){
this.count--
})
}
}
function main(){
obj = new ActiveObject()
obj.increment_count()
obj.decrement_count()
}Here's a step-by-step guide on what's happening:
- When we create an instance of
ActiveObject, we create a new thread that runs therun_tasksmethod. - The
run_tasksmethod waits for any other methods in ourdispatch_queueand runs them. - Our other methods such as
increment_countanddecrement_countpush their logic as functions to thedispatch_queue.
Monitor Object
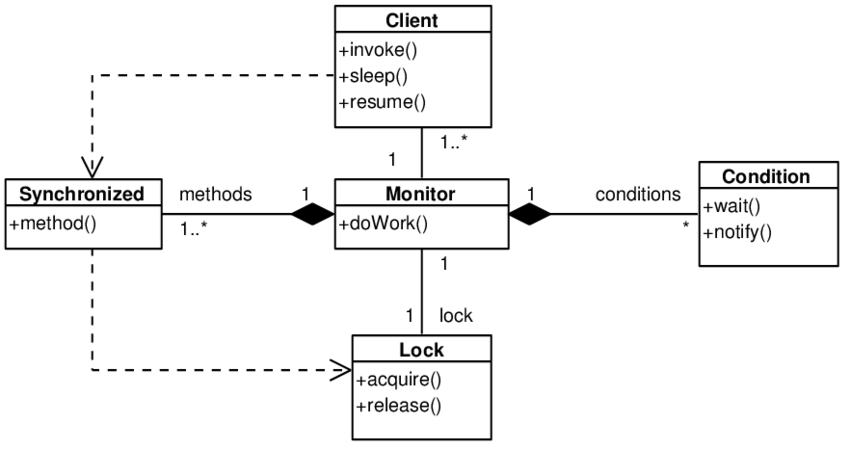
Monitor object is a design pattern that is used to create thread-safe objects and prevent conflicts between threads in concurrent applications.
You might ask ''what is thread-safe?"
Simply, thread-safe means that a method or class instance can be used by multiple threads at the same time without any problems.
For example, let's consider this example:
counter = 0;
function increment()
{
tmp = counter;
tmp = counter + 1;
counter = tmp;
return tmp;
}If we have two threads running the function increment, then thread-1 might execute the data and conclude that counter is 0, thread-2 also started running concurrently and also concluded that counter is 0. In the end, the counter was incremented once even though it was run by two threads simultaneously.
These kinds of problems where data is being used improperly in multithreaded environments are called race conditions.
Locking data is one mechanism to fix that and this is how monitor objects work to keep data synchronised between multiple threads.
It's pretty simple to implement, so here's the pseudocode.
class MonitorObject {
lock myLock
count = 0
function increment(){
this.myLock.acquire()
try {
this.count++
} finally {
this.myLock.release()
}
}
function decrement(){
this.myLock.acquire()
try {
this.count--
} finally {
this.myLock.release()
}
}
}This is as simple as it can get.
We simply use a lock to safely mutate our data.
Most programming languages have some syntactic sugar to make it easier to implement this pattern. For example, Java has the "synchronized" methods to easily prevent data from being accessed by multiple threads at once.
Balking Pattern
The Balking Pattern is used to prevent an object from executing a certain code if it is in an incomplete or inappropriate state.
You would usually use this pattern when:
- You got a method that would only work on an object with a specific state.
- Objects are generally in an inappropriate state for an indefinite amount of time, hence that's why we "balk" our methods.
Let's expand on our counter-example, if our counter is 0 then we cannot decrement it.
To implement this functionality using the Balking pattern, we would do something like this:
class BalkingObject {
lock myLock
count = 0
function increment(){
this.myLock.acquire()
try {
this.count++
} finally {
this.myLock.release()
}
}
function decrement(){
this.myLock.acquire()
try {
if (this.count <= 0){
// do nothing
return
}
this.count--
} finally {
this.myLock.release()
}
}
}In a nutshell, this is more of a Monitor Object Pattern with conditionals based on state.
There are some computer scientists who regard the Balking Pattern as an anti-pattern but in general, it's up to you to decide whether it fits your needs or not.
Other than that, there are a few alternatives if you know that an object will be in an inappropriate state for a finite amount of time. It will be better if you use the Guarded Suspension Pattern.
You can read more about it here:
Contributors to Wikimedia projects
Producer-Consumer Pattern
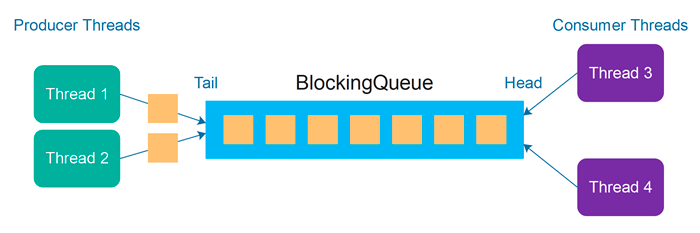
The Producer-Consumer Pattern is a classic concurrency design pattern that separates method invocation from method execution.
It does that by designating processes as either:
- Producer – The producer would push work into the queue for later processing instead of processing them immediately.
- Consumer – The consumer would then take a work item from the queue and process it whenever it's free.
These are the common use cases for this pattern:
- Reduce foreground thread latency – Usually, you would have one foreground thread communicating with the outside world. For example, in a web app, this thread will handle HTTP requests. The issue arises if the requests become expensive and take a lot of time to compute, then this thread is blocking other incoming requests. So the solution is for this thread to give the execution of the HTTP request to some other background thread so it can be free to accept other HTTP requests.
- Load balance work between different threads – If you got expensive actions, you can load balance them to run efficiently in multiple threads.
- Backpressure Management – Backpressure happens when your producer is giving out more work than the consumers can handle. If you have a finite queue, the queue will essentially fill up and this will block your producers from pushing more work into the queue. This is called backpressure. The system presses back against the producers.
Now let's look at how to implement this pattern.
One non-common way to implement the Producer-Consumer Pattern is to use Semaphores.

A Semaphore is a data structure that helps threads work together without interfering with each other.
The POSIX standard specifies an interface for semaphores; it is not part of Pthreads, but most UNIXes that implement Pthreads also provide semaphores.
This is the interface defined for POSIX Semaphores:
typedef sem_t Semaphore;
Semaphore *make_semaphore(int value);
void semaphore_wait(Semaphore *sem);
void semaphore_signal(Semaphore *sem);Let's quickly go over the methods:
make_semaphore– This is our semaphore creation function, it takes the initial value of the semaphore as a parameter. It allocates space, initializes it, and returns a pointer to Semaphore.semaphore_wait– This function decrements the semaphore count. If the semaphore count is negative after decrementing, the calling thread blocks.semaphore_signal– This function increments the semaphore count. If the count goes non-negative (i.e. greater than or equal to 0) and a thread is blocked on the semaphore, then the waiting thread is scheduled to execute.
Using semaphores, we can implement a simple producer-consumer:
Semaphore *mutex = make_semaphore(0);
Semaphore *empty = make_semaphore(0);
Semaphore *full = make_semaphore(0);
Array buffer = []
function producer(){
do {
// produce item
semaphore_wait(empty);
semaphore_wait(mutex);
// put item in buffer
semaphore_signal(mutex);
semaphore_signal(full);
} while(1);
}
function consumer(){
do {
wait(full);
wait(mutex);
// remove item from buffer
signal(mutex);
signal(empty);
// consume item
} while(1);
}Barrier Pattern
The best definition I got about this is from Wikipedia:
In parallel computing, a barrier is a type of synchronization method. A barrier for a group of threads or processes in the source code means any thread/process must stop at this point and cannot proceed until all other threads/processes reach this barrier.
It's pretty self-explanatory, the barrier stops all threads from proceeding until all other threads reach this barrier.
Let's look at a basic example. The basic barrier has two main variables:
- One of which records the pass/stop state of the barrier.
- The other of which keeps the total number of threads that have entered the barrier.
The initial state of the barrier is "stop". When a thread enters, and if it is the last thread, then the state of the barrier will change to "pass" so that all the other threads can get out of the barrier. On the other hand, when the incoming thread is not the last one, it is trapped in the barrier and keeps testing if the barrier state has changed from "stop" to "pass", and it gets out only when the barrier state changes to "pass".
Here's a C++ example I copied from Wikipedia:
struct barrier_type
{
// how many processors have entered the barrier
// initialize to 0
int arrive_counter;
// how many processors have exited the barrier
// initialize to p
int leave_counter;
int flag;
std::mutex lock;
};
// barrier for p processors
void barrier(barrier_type* b, int p)
{
b->lock.lock();
if (b->arrive_counter == 0)
{
b->lock.unlock();
while (b->leave_counter != p); // wait for all to leave before clearing
b->lock.lock();
b->flag = 0; // first arriver clears flag
}
b->arrive_counter++;
if (b->arrive_counter == p) // last arriver sets flag
{
b->arrive_counter = 0;
b->leave_counter = 0;
b->flag = 1;
}
b->lock.unlock();
while (b->flag == 0); // wait for flag
b->lock.lock();
b->leave_counter++;
b->lock.unlock();
}Double Checked Locking
Double-Checked locking is a design pattern used to reduce the overhead of acquiring a lock by first testing the locking criterion (the "lock hint") before acquiring the lock.
You can think of this as lazy initialization, you only initialize a variable when you need it.
This is an example of the pattern:
class Foo {
private Helper helper;
public Helper getHelper() {
if (helper == null) {
synchronized (this) {
if (helper == null) {
helper = new Helper();
}
}
}
return helper;
}
// other functions and members...
}Essentially it checks whether our helper exists. If not then it will acquire a lock and initialize a helper so that other threads can access the helper without acquiring any lock.
Leaders/Followers Pattern
PS. For the following pattern, I've literally copied a StackOverflow answer from here.
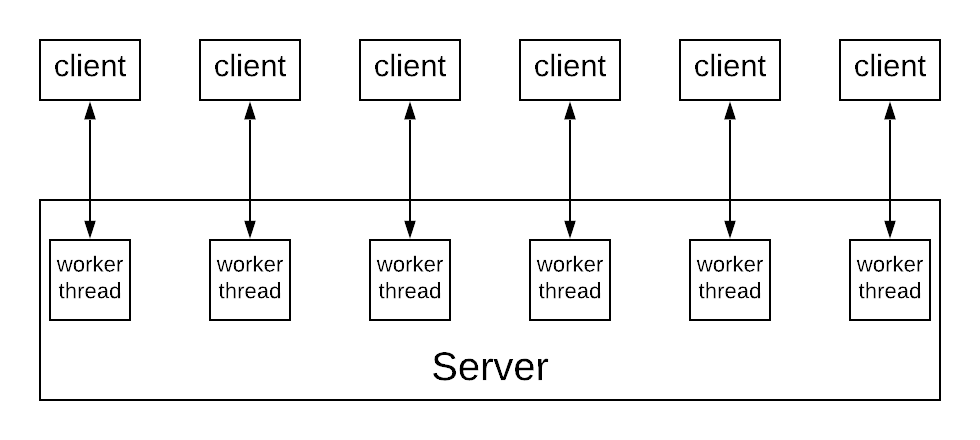
Most people are familiar with the classical pattern of using one thread per request. This can be illustrated in the following diagram. The server maintains a thread pool and every incoming request is assigned a thread that will be responsible to process it.
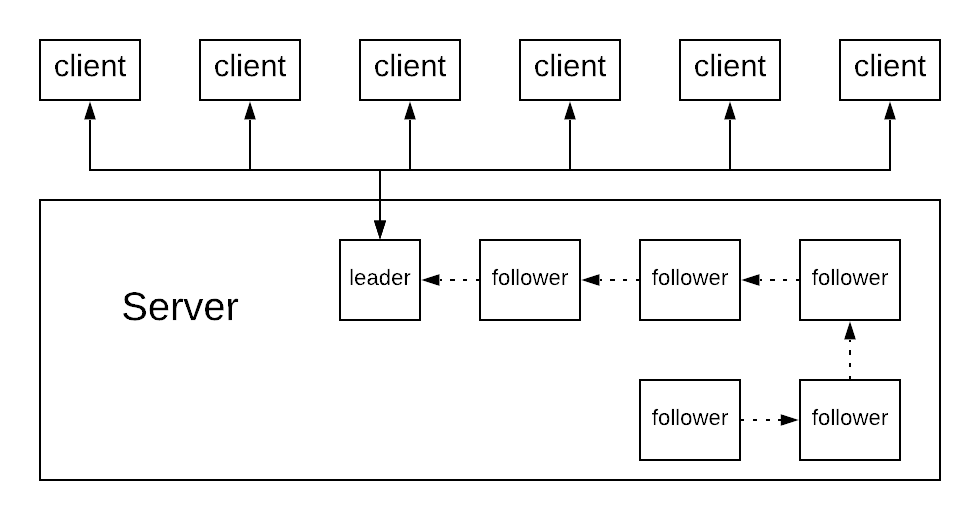
In the leader/follower pattern, one of these threads is designated as the current leader. This thread is responsible for listening to multiple connections. When a request comes in:
- First, the thread notifies the next (follower) thread in the queue, which becomes the new leader and starts listening for new requests
- Then, the thread proceeds with processing the request that was received previously.
The following diagram illustrates how that works at a high level.
We've only scratched the surface with this pattern if you want to learn more. This is an excellent paper on the leader/followers pattern.
http://www.kircher-schwanninger.de/michael/publications/lf.pdf
Conclusion
Well that was long, I'm sure I`ve missed many others.
If I did or wrote anything wrong, feel free to critique me on Twitter.
Thanks for reading.
No spam, no sharing to third party. Only you and me.
Member discussion