Working Effectively with Legacy Code: Chapter 2 Summary

In this chapter, we will cover the different ways changes happen in our system.
In general, there are two ways:
- Edit and Pray
- Cover and Modify
Unfortunately, Edit and Pray is industry standard.
The process of Edit and Pray goes like this:
- Carefully plan the changes you are going to make.
- You make sure that you understand the code you are going to modify.
- Start to make the changes.
- You run the system to see if the change was enabled.
- Finally, you poke around further to make sure that you didn’t break anything.
The poking around is the Pray part, you are essentially hoping and praying that you didn't break anything.
You might argue that Edit and Pray is a very professional thing to do because you are "working with care"?
I got a question for you.
Would you choose a surgeon who operated with a butter knife just because he worked with care?
No, me too.
The whole system itself is wrong.
Fortunately, we have another system called Cover and Modify.
The general idea of this methodology is to work with a safety net.
The safety net are tests.
But there are different kinds of tests?
There are tests to:
- Show correctness (your typical testing).
- Detect changes (also called regression testing).
The tests that we care about in this chapter are the second type which are called regression tests.
Unit Testing
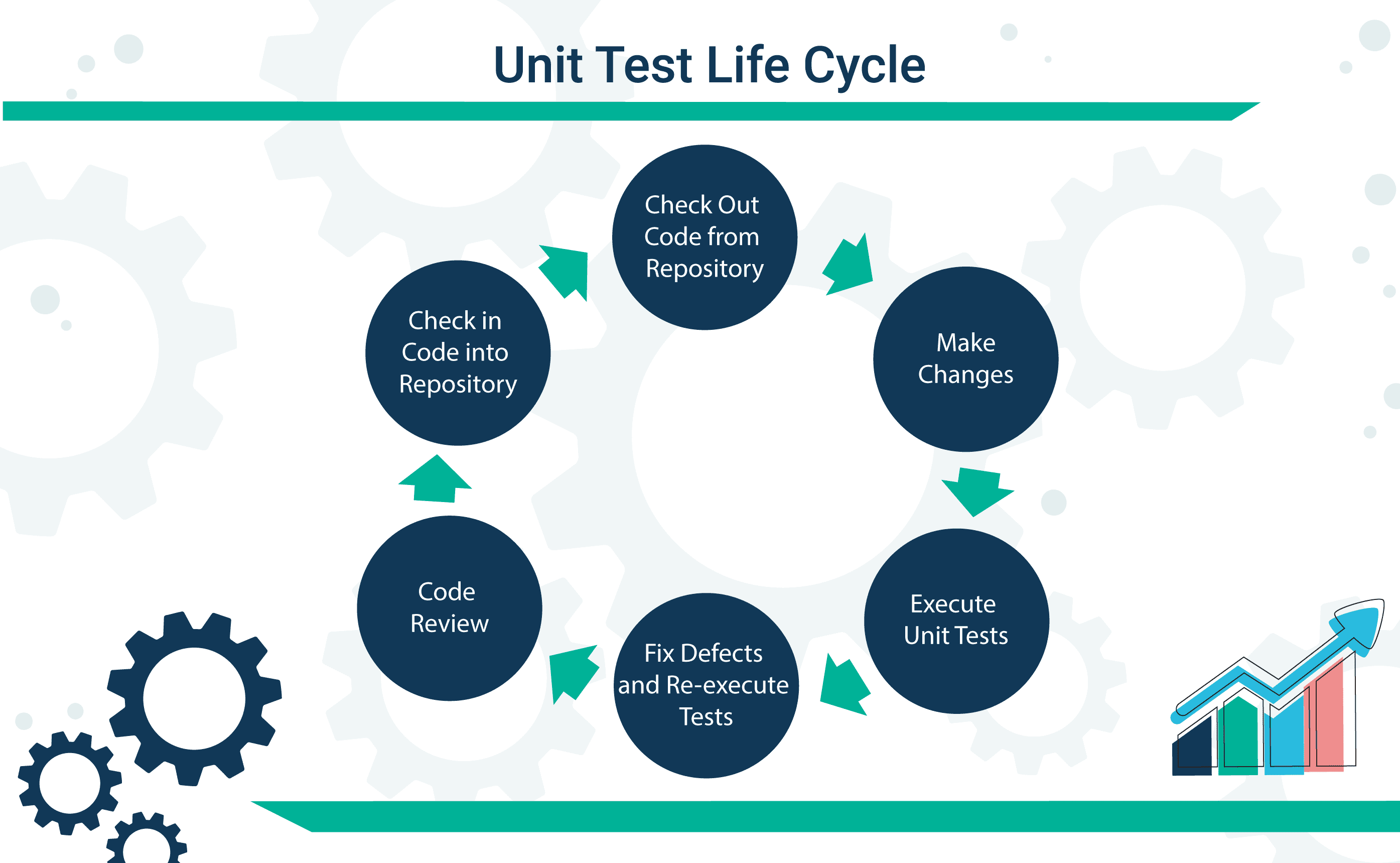
Usually, when people do regression testing, they test on the application level:
- If it's a web API, then they would do an HTTP request to test the API.
- If it's a CLI program, they would call the command itself.
- If it's a GUI application, then they would test by programmatically trigging events on the GUI.
The problem with this is that it's slow and has a lot of headaches. Lots of different things can go wrong such as network errors, or the test is just way too big and fails in multiple ways.
The better option would be to test components independently. This way it will be faster, and more precise.
These kinds of tests are called Unit Tests.
But how big should a unit test be?
We mentioned that a unit test should only test a single component.
But how do we define components?
This is what Michael Feathers says:
The definition varies, but in unit testing, we are usually concerned with the most atomic behavioral units of a system. In procedural code, the units are often functions. In object-oriented code, the units are classes.
Now that we know how big our components should be, let's talk about the benefits of this approach:
- Error Localization – The bigger the tests are the harder it is to detect what a test failure means. This is because at that point, you aren't testing one thing, but multiple different things that have different results depending on the scenario.
- Execution Time – Larger tests tend to take longer to execute. This tends to make test runs rather frustrating. Tests that take too long to run end up not being run.
- Coverage – It is hard to see the connection between a piece of code and the values that exercise it. We can usually find out whether a piece of code is exercised by a test using coverage tools, but when we add new code, we might have to do considerable work to create high-level tests that exercise the new code.
In a nutshell, how would you know whether you have a good unit test or not?
It should be fast and local.
Programmers usually debate whether a piece of test is a unit test or not.
In general, if it's fast (by fast I mean less than a 1/10th of a second) and local then its a unit test.
If it talks to the:
- Database
- Network
- File System
- Special Environments.
Then it's not a unit test.
Higher Level Testing
Sometimes, unit tests are not enough because you have multiple components talking to each other, in this case, we need some higher-level tests.
In this case, you would benefit from integration tests or end-to-end tests.
This is out of the scope of the book because it mainly talks about unit tests.
Legacy Code Change Algorithm
The reason why most programmers don't write tests for legacy code is that it's just too hard and bothersome.
The reason why its hard to test is that there are too many damn dependencies.
You want to test class A but class A depends on class B, at the same time class B depends on a dozen other classes.
In the end, this puts you in the legacy code dilemma.
When we change code, we should have tests in place. To put tests in place, we often have to change code – Michael Feathers
You might be thinking there must be a secret formula, some one-thing that I can do that will make breaking dependencies easier.
Unfortunately, there's none.
But the next best is some sort of formula to help you when your refactoring legacy code.
We call it The Legacy Code Change Algorithm
It goes like this:
- Identify change points
- Find test points
- Break dependencies
- Write tests
- Make changes and refactor
Conclusion
This is all easier said than done, this book covers in-depth the five steps in our Legacy Code Change Algorithm.
I know this was a pretty short article but I got a ton of stuff on my plate this week.
Thanks for reading.
No spam, no sharing to third party. Only you and me.
Member discussion