Working Effectively with Legacy Code: Chapter 7 Summary

How long does it take for you to make a change?
If I ask this to 100 different people, I will get 100 different answers.
The answer varies widely.
So in projects with unclear code, many changes take a long time. On the other hand, in clearer areas, this can be very quick. In very tangled areas, it can take a very long time.
Some teams have it much worse. Even the simplest changes can take hours to implement. People on those teams can figure out what they need to do and implement the change in 5 minutes but still won't be able to deploy for hours.
But why does this happen and are there any solutions?
Hi, I'm summarizing the book "Working Effectively with Legacy Code". If you are interested in the book, feel free to check it out here.
Why do changes take a long time?
Understanding
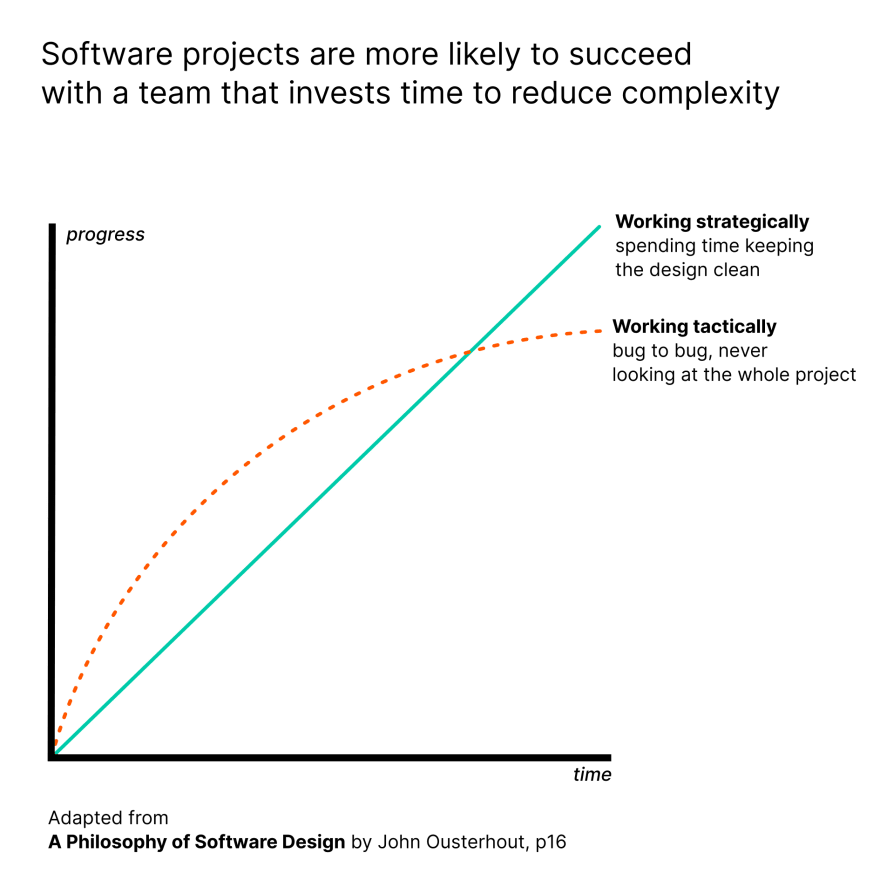
As the codebase grows, it gradually surpasses understanding. The amount of time it takes to figure out what to change keeps increasing.
This is unavoidable because there is no stopping adding new code. It's just gonna take us time to figure out how to make a change if we are unfamiliar with the context.
However, if your system is well-maintained meaning that it's broken up into small, well-named, and understandable pieces then it might take a while to figure out how to make a change, but once you do, the change is usually easy and you feel much more comfortable with the system.
In legacy systems, it will take a long time to figure out what to do and the change is difficult to do. You might even not be confident that the change will not break anything else, so you resort to the classic strategy of edit and pray.
Lag Time

Lag time is the time between you making your change and you getting real feedback about the change.
For example, the Mars rover Spirit is going around taking pictures. It takes about 7 minutes for signals to get from Earth to Mars. Luckily Spirit has autonomous driving but imagine if you had to do that manually?
That would be very inefficient, it would take you 14 minutes to know how far the rover moved. Yet, when we think about it, that is exactly the way most engineers develop their software.
We make a change, start a build, and then manually check if our code works. This is how it is in some languages but in most mainstream programming languages nowadays you can recompile and run tests in less than 10 seconds.
But that's not always the case. Sometimes you just don't have any tests and you have to manually check if your code works. Other times, the tests are just too slow and it takes you a long time to get feedback.
The main point is that we have to minimize this lag time as much as possible because the longer it is the less efficient we are and most importantly it stops us from getting into the focus zone.
Breaking Dependencies

The bane of our code is tangled dependencies but fortunately, we can break them. Sometimes it's easy just instantiate the class that you need other times it's difficult.
For example, you want to get class A under tests but class A depends on class B. Your like okay? Let's simply instantiate class B but here comes the tricky part, class B makes real database calls.
You are now stuck in a dilemma, do you break the concrete dependency between class A and class B or do you just run tests with database calls?
I was being sarcastic about the dilemma, the obvious choice is to break dependencies.
But how do we do that?
Well, let's welcome the D from the S.O.L.I.D principles which is the Dependency Inversion Principle.
PS. If you are interested in learning more about the SOLID principles. I wrote a whole series on them here.
 Tamerlan Gudabayev
Tamerlan Gudabayev
Dependency Inversion Principle
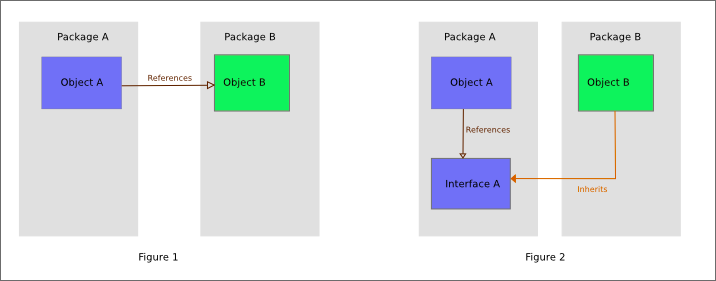
The dependency inversion principle states:
Entities must depend on abstractions, not on concretions. It states that the high-level module must not depend on the low-level module, but they should depend on abstractions.
Let's take an example.
We have a PasswordHasher class that connects to a MySQL database.
class MySQLConnection
{
public function connect()
{
// handle the database connection
return 'Database connection';
}
}
class PasswordHasher
{
private $dbConnection;
public function __construct(MySQLConnection $dbConnection)
{
$this->dbConnection = $dbConnection;
}
}The problem that our high-level entity which is PasswordHasher depends upon a low-level module which is our MySQLConnection.
This class works but has major flaws:
- Adaptability – Our
PasswordHashercurrently uses a MySQL database but what if in the future we want to change that and use some other database or even a file system instead. Currently, this change is difficult to make because ourPasswordHasheris tangled withMySQLConnection. - Testability – To test our
PasswordHasher, we will have to instantiate it but if we do it requires aMySQLConnectionwhich will open a real connection to our database which we don't want.
Okay, I get it.
So how do we fix this?
It's simple, as the principle says, "high-level modules must not depend on the low-level module, but they should depend on abstractions".
With that in mind, let's abstract our database connection by creating a DBConnectionInterface and having our PasswordHasher depend on that.
interface DBConnectionInterface
{
public function connect();
}
class MySQLConnection implements DBConnectionInterface
{
public function connect()
{
// handle the database connection
return 'Database connection';
}
}
class PasswordHasher
{
private $dbConnection;
public function __construct(DBConnectionInterface $dbConnection)
{
$this->dbConnection = $dbConnection;
}
}Now we solved the two major flaws that we had before. If we ever need to change databases, we can essentially create new classes that implement DBConnectionInterface. We can easily our PasswordHasher with a MockDatabase which implements DBConnectionInterface.
Conclusion
This was a pretty short chapter but we learned a ton. Here's a summary of the chapter.
- If your code is all tangled, it will take a long time to figure out what is happening and where to make a change.
- On the other hand, clear code is easier to understand and you can more confidently make your changes.
- To be more efficient minimize lag time.
- Be very careful when depending on concrete classes, remember the dependency inversion principle.
Thanks for reading.
No spam, no sharing to third party. Only you and me.
Member discussion